
The robots.txt file is a simple text file that helps you control how search engine crawlers access your website. It’s one of the most underutilized tools for SEO and content marketing, but also one of the easiest to implement.
What is a robots.txt file?
A robots.txt file is a text file that tells search engines what to do with different parts of your website. If a page or a folder on your site is not listed in the robots.txt file, search engines will assume that they can crawl them and index them as normal.
The robots.txt file is placed in the root directory of your website and it’s not required for it to be indexed by search engines; however, by adding one you can make sure that certain pages aren’t included in their results (or are included with specific directives). It’s also used as an opportunity to communicate information about how users should interact with your site (for example, telling them how many links there are on each page).
How Does Robots.txt Help My Website?
Robots.txt is a file that helps you control how search engines crawl, index and display your site.
Robots.txt can help you get more traffic to your website by telling search engines the parts of a page they shouldn’t crawl or index. It does this by specifying which URLs should be ignored for indexing purposes (i.e., blocked). It also makes it possible to specify different content for mobile devices than for desktop computers, so when people visit the same URL from both devices simultaneously, they see different things!
How Can I Add Robots.txt To WordPress?
Adding a robots.txt file to your website is really easy and can be done in three steps:
- Create the robots.txt file. This file will be added to the root of your site, so if you want it on a subdomain, for example, “example-blog.com/robots.txt” or “www.example-blog.com/robots.txt” will be required (for security reasons). You can create this file manually with any text editor or through FTP software like FileZilla or Cyberduck if you prefer not having to go into WordPress itself and add it that way; just make sure that whatever method you choose automatically creates an empty line at the end of the document so it doesn’t look weird when viewed by search engines!
What Sorts Of Rules Can I Put In Robots.txt?
The most common robots.txt rules are:
- Allow or disallow particular bots from making requests to your website. For example, you might want to allow search engine crawlers and block everything else. All search engines come with their own user agent names which crawlers will follow based on how specific it is and the rules set for them with the name separated by hyphens, and if an exact match is not found then it will fall back to more generic rules. For example, Googlebot Image would look for a match of ‘googlebot-image’, then ‘googlebot’, then ‘*’.
Examples of the most common user agent tokens can be found below:
* – These rules apply to every bot, unless there is a more specific set of rules
- Googlebot – All Google crawlers
- Googlebot-News – Crawler for Google News
- Googlebot-Image – Crawler for Google Images
- Mediapartners-Google – Google Adsense crawler
- Bingbot – Bing’s crawler
- Yandex – Yandex’s crawler
- Baiduspider – Baidu’s crawler
- Facebot – Facebook’s crawler
- Twitterbot – Twitter’s crawler
How Do I Test My Robots.txt File?
To test your robots.txt file, you can use one of the following methods:
- Use a search engine like Google or Bing to visit your site.
- Check the URL that is generated when you type in the domain name (www.example.com) into a browser window and add Robots=User-agent:*.*? to the end of it (you don’t have to include all those zeros). This will tell you if there is a robots meta tag present in your section on http://www..com/. You can also check for its presence at https://.com/.
After checking these places, if you still haven’t found any mention of a robots meta tag, then it’s safe to assume that either no one has used them before or they’ve been overlooked by previous developers who built out their sites’ architecture; both are situations where implementing one now would be ideal!
How Do Big WordPress Websites Implement Robots.txt?
A number of big-name WordPress websites use robots.txt, and they do so in different ways.
- Googlebot: Google crawls through a large percentage of the Internet every day, picking up new content and updating its index as it goes along. In addition to its own web crawler, Google also has an official policy on how other companies can block access to certain parts of their website using robots.txt files. The most important thing for you to remember is that if you don’t want your site crawled by Googlebot, you need to add the word “noindex” into your robots file (for example: User-agent: * Disallow: /).
- Bingbot: Microsoft’s Bing search engine also follows similar guidelines outlined by Google when it comes to crawling sites with blocked areas via a robots file. If you want your site blocked from being crawled by Bingbot’s bot (which is named “Slurp”), then simply add “User-agent:” followed by whatever agent name applies in your case into your robots file (for example: User-agent: bingbot).
Robots.txt Example Files
If you are still unsure about what you should have in your Robots.txt file then we have included a few examples below for sites with few and many, pages, along with some more direct examples:
- Few Pages:
User-agent: *
Disallow: /wp-admin/
Disallow: /wp-includes/
Disallow: /wp-content/plugins/mig/files/
- Many Pages:
User-agent: *
Disallow: /product-category/*
User-agent: Googlebot
Disallow: /*?id=1
User-agent: SlippyLizardBot (TM)
Allow:/wp/
- Allowing all web crawlers/robots access to all your sites content:
User-agent: * Disallow:
- Blocking all web crawlers/bots from all your sites content:
User-agent: * Disallow: /
It is incredibly easy it is to make a mistake when creating your sites robots.txt since the only thing from blocking your entire site from being seen is a simple forward slash.
- Blocking a specific web crawlers/bots from a specific folder:
User-agent: Googlebot Disallow: /
- Blocking a web crawlers/bots from a specific page on your site:
User-agent: Disallow: /thankyou.html
- Exclude all robots from part of the server:
User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /junk/
Use a Dedicated Robots.txt Plugin
There is an even easier approach to incorporating a robots.txt file into your website and that is through the use of the many plugins you can find online. However, today we will be focusing on just one called Virtual Robots.txt.
Virtual Robots.txt is an easy (i.e. automated) solution to creating and managing a robots.txt file for your site. Instead of mucking about with FTP, files, permissions ..etc, just upload and activate the plugin and you’re done.
Marios Alexandrou
Here is how to use the Virtual Robots.txt plugin:
- Download Virtual Robots.txt from the WordPress website or for simplicity, we have included the direct link from wordpress.org here. Then upload the plugin to your WordPress website by clicking Plugins->Add New and then clicking Upload Plugin on the page. You may also search for this plugin in your WordPress dashboard by clicking Plugins->Add New and then searching for it in the search box.
- Install & Activate
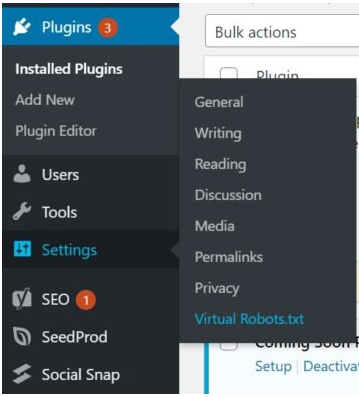
- Navigate to Settings and click Virtual Robots.txt
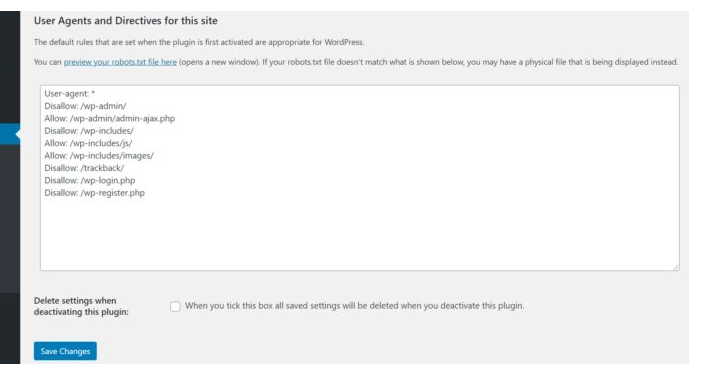
- Now you are able to see your robots.txt file and modify it. When you are done, click Save Changes and then you will be finished.
Conclusion
That’s it! You now have a good understanding of WordPress robots.txt and what you can do with it. I hope my guide has cleared up any confusion or questions you may have had about this powerful tool, so now that you know what it is, go out there and make some magic with your website!













